
Giới thiệu
Bài viết này là phần tiếp nối của loạt bài dành cho người mới bắt đầu. Ở đây, tôi giả định rằng người đọc đã nắm được nội dung từ hai bài viết trước.
Bài viết đầu tiên là phần giới thiệu. Nó giả định rằng người đọc không có kinh nghiệm lập trình trước đó, giới thiệu các công cụ cần thiết cho lập trình viên, mô tả các loại chương trình chính và giới thiệu một số khái niệm cơ bản, đặc biệt là khái niệm về function.
Bài viết thứ hai mô tả các thao tác với dữ liệu. Nó giới thiệu các khái niệm như literal, variable, data type, operator, v.v., và xem xét các toán tử chính để modification dữ liệu: số học, logic, bitwise và các loại khác.
Trong bài viết này, tôi sẽ mô tả cách lập trình viên corrido thể tạo ra các kiểu dữ liệu phức tạp:
- Kết cấu (Structures)
- Liên kết (Union)
- Lớp (Classes) - ở cấp độ người mới bắt đầu
- Các kiểu cho phép sử dụng tên biến như một hàm. Điều này cho phép, trong số những thứ khác, truyền hàm làm tham số cho các hàm khác.
Bài viết cũng mô tả cách bao gồm các tệp văn bản bên ngoài bằng chỉ thị tiền xử lý #include để đảm bảo chương trình của chúng ta có tính mô-đun và linh hoạt. Tôi xin nhắc lại rằng dữ liệu có thể được tổ chức theo nhiều cách khác nhau, nhưng trình biên dịch phải luôn biết chương trình của chúng ta sẽ cần bao nhiêu bộ nhớ, do đó trước khi sử dụng dữ liệu, nó phải được mô tả bằng cách chỉ định kiểu của nó.
Các kiểu dữ liệu đơn giản như double, enum, string, v.v., đã được mô tả trong bài viết thứ hai. Nó đã xem xét chi tiết cả biến (dữ liệu thay đổi trong quá trình hoạt động) và hằng số. Tuy nhiên, khi lập trình, thường xuất hiện các tình huống mà việc tạo ra các kiểu phức tạp hơn từ dữ liệu đơn giản sẽ tiện lợi hơn. Chính những “cấu trúc” này sẽ được chúng ta thảo luận trong phần đầu của bài viết này.
Càng có modular structure trong chương trình, việc phát triển và bảo trì nó càng dễ dàng. Điều này đặc biệt quan trọng khi làm việc nhóm. Ngay cả đối với “nhà phát triển đơn lẻ”, việc tìm lỗi trong một đoạn mã ngắn cũng dễ hơn nhiều so với trong một đoạn mã dài dòng. Đặc biệt nếu bạn quay lại mã sau một thời gian dài để thêm tính năng mới hoặc sửa một số lỗi logic không dễ nhận thấy ngay lập tức.
Nếu bạn cung cấp các cấu trúc dữ liệu phù hợp, tách các hàm tiện lợi thay vì sử dụng danh sách dài các điều kiện và vòng lặp, đồng thời phân phối các khối mã liên quan logic vào các tệp khác nhau, việc thực hiện thay đổi sẽ dễ dàng hơn nhiều.
Kết cấu (Structures)
Kết cấu mô tả một tập hợp dữ liệu phức tạp có thể được lưu trữ thuận tiện trong một biến duy nhất. Ví dụ, thông tin về thời gian thực hiện một giao dịch trong ngày nên bao gồm giờ, phút và giây.
Tất nhiên, bạn có thể tạo ba biến cho từng thành phần và truy cập từng biến khi cần. Tuy nhiên, vì các biến này là một phần của một mô tả duy nhất và thường được sử dụng cùng nhau, nên việc mô tả một kiểu riêng cho dữ liệu như vậy là tiện lợi. Kết cấu cũng có thể chứa dữ liệu bổ sung của các kiểu khác, chẳng hạn như múi giờ hoặc bất kỳ thứ gì lập trình viên cần.
Trong trường hợp đơn giản nhất, kết cấu được mô tả như sau:
struct IntradayTime {
int hours;
int minutes;
int seconds;
string timeCodeString;
}; // lưu ý dấu chấm phẩy sau dấu ngoặc nhọnVí dụ 1. Một ví dụ về kết cấu để mô tả thời gian giao dịch.
Mã này tạo ra một kiểu dữ liệu mới IntradayTime. Trong dấu ngoặc nhọn của khai báo này, bạn có thể thấy tất cả các biến mà chúng ta muốn kết hợp. Do đó, tất cả các biến thuộc kiểu IntradayTime sẽ chứa giờ, phút và giây.
Mỗi phần của kết cấu trong mỗi biến có thể được truy cập thông qua dấu chấm ”.”.
IntradayTime dealEnterTime;
dealEnterTime.hours = 8;
dealEnterTime.minutes = 15;
dealEnterTime.timeCodeString = "GMT+2";Ví dụ 2. Sử dụng biến kiểu kết cấu.
Khi chúng ta mô tả một kết cấu, các biến “nội bộ” của nó (thường được gọi là fields) có thể có any kiểu dữ liệu hợp lệ nào, bao gồm cả việc sử dụng các kết cấu khác. Ví dụ:
// Kết cấu lồng nhau
struct TradeParameters
{
double stopLoss;
double takeProfit;
int magicNumber;
};
// Kết cấu chính
struct TradeSignal
{
string symbol; // Tên biểu tượng
ENUM_ORDER_TYPE orderType; // Loại lệnh (BUY hoặc SELL)
double volume; // Khối lượng lệnh
TradeParameters params; // Kết cấu lồng nhau làm kiểu tham số
};
// Sử dụng kết cấu
void OnStart()
{
// Mô tả biến cho kết cấu
TradeSignal signal;
// Khởi tạo các trường của kết cấu
signal.symbol = Symbol();
signal.orderType = ORDER_TYPE_BUY;
signal.volume = 0.1;
signal.params.stopLoss = 20;
signal.params.takeProfit = 40;
signal.params.magicNumber = 12345;
// Sử dụng dữ liệu trong một biểu thức
Print("Symbol: ", signal.symbol);
Print("Order type: ", signal.orderType);
Print("Volume: ", signal.volume);
Print("Stop Loss: ", signal.params.stopLoss);
Print("Take Profit: ", signal.params.takeProfit);
Print("Magic Number: ", signal.params.magicNumber);
}Ví dụ 3. Sử dụng kết cấu để mô tả kiểu của các trường của một kết cấu khác.
Nếu bạn sử dụng hằng số thay vì biểu thức làm giá trị khởi tạo cho một kết cấu, bạn có thể sử dụng ký hiệu ngắn gọn để khởi tạo. Ở đây bạn nên sử dụng dấu ngoặc nhọn. Ví dụ, khối khởi tạo từ ví dụ trước có thể được viết lại như sau:
TradeSignal signal =
{
"EURUSD",
ORDER_TYPE_BUY,
0.1,
{20.0, 40.0, 12345}
};Ví dụ 4. Khởi tạo một kết cấu bằng hằng số.
Thứ tự của các hằng số phải khớp với thứ tự của các trường trong mô tả. Bạn cũng có thể khởi tạo chỉ một phần của kết cấu bằng cách liệt kê các giá trị cho các trường initial. Trong trường hợp này, tất cả các trường khác sẽ được khởi tạo bằng số không.
MQL5 cung cấp một set of predefined kết cấu, chẳng hạn như MqlDateTime, MqlTradeRequest, MqlTick, và các loại khác. Theo quy tắc, việc sử dụng chúng không phức tạp hơn những gì được mô tả trong phần này. Danh sách các trường của những kết cấu này và nhiều kết cấu khác được mô tả chi tiết trong tài liệu tham khảo ngôn ngữ.
Ngoài ra, danh sách này cho bất kỳ kết cấu nào (và các kiểu phức tạp khác) đều hiển thị trong MetaEditor khi bạn tạo một biến của kiểu mong muốn, sau đó gõ tên của nó và nhấn dấu chấm (”.”) trên bàn phím.
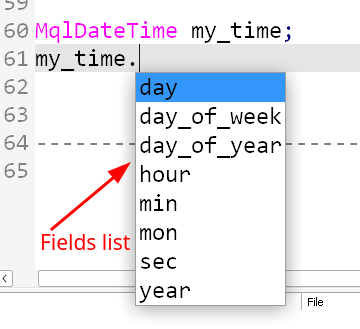
Hình 1. Danh sách các trường của kết cấu trong MetaEditor.
Tất cả các trường của kết cấu mặc định đều khả dụng cho tất cả các hàm của chương trình của chúng ta.
Về Kết cấu trong MQL5: Một vài lời dành cho những ai biết cách làm việc với DLL bên ngoài
Cảnh báo. Phần này có thể khó đối với người mới bắt đầu, vì vậy khi đọc bài viết lần đầu, bạn có thể bỏ qua nó và chuyển thẳng đến unions, sau đó quay lại phần này sau.
Theo mặc định, dữ liệu trong các kết cấu MQL5 được đặt ở dạng đóng gói, tức là trực tiếp nối tiếp nhau, vì vậy nếu bạn muốn kết cấu chiếm một số byte nhất định, bạn có thể cần thêm các phần tử bổ sung.
Trong trường hợp này, tốt hơn là đặt dữ liệu lớn nhất trước, sau đó đến dữ liệu nhỏ hơn. Cách này có thể tránh được nhiều vấn đề. Tuy nhiên, các kết cấu MQL5 cũng có khả năng “căn chỉnh” dữ liệu bằng cách sử dụng một toán tử đặc biệt pack:
struct pack(sizeof(long)) MyStruct1
{
// các thành viên của kết cấu sẽ được căn chỉnh trên ranh giới 8 byte
};
// hoặc
struct MyStruct2 pack(sizeof(long))
{
// các thành viên của kết cấu sẽ được căn chỉnh trên ranh giới 8 byte
};Ví dụ 5. Căn chỉnh kết cấu.
Bên trong dấu ngoặc của pack, bạn chỉ có thể sử dụng các số 1, 2, 4, 8, 16.
Lệnh đặc biệt offsetof sẽ cho phép bạn lấy độ lệch tính bằng byte cho bất kỳ trường nào của kết cấu so với điểm bắt đầu. Ví dụ, nếu chúng ta lấy kết cấu TradeParameters từ ví dụ 3, bạn có thể sử dụng mã sau để lấy độ lệch của trường stopLoss:
Print (offsetof(TradeParameters, stopLoss)); // Kết quả: 0Ví dụ 6. Sử dụng toán tử offsetof.
Các kết cấu KHÔNG chứa chuỗi, mảng động, đối tượng dựa trên lớp, và con trỏ được gọi là đơn giản. Biến của các kết cấu đơn giản, cũng như các mảng gồm các phần tử như vậy, có thể được truyền tự do đến các hàm nhập từ thư viện DLL bên ngoài.
Cũng có thể sao chép các kết cấu simple vào nhau bằng toán tử gán, nhưng chỉ trong hai trường hợp:
- Hoặc các biến có kiểu
same; - Hoặc các kiểu biến liên quan bởi một đường
directinheritance.
Điều này có nghĩa là nếu chúng ta đã định nghĩa các kết cấu “plants” và “trees”, bất kỳ biến nào của “plants” có thể được sao chép vào bất kỳ biến nào được tạo dựa trên “trees”, và ngược lại. Tuy nhiên, nếu chúng ta cũng có “bushes”, thì bạn chỉ có thể sao chép từ “bushes” sang “trees” (hoặc ngược lại) từng phần tử một.
Trong all other cases, ngay cả các kết cấu có cùng các trường cũng phải được sao chép element by element.
Các quy tắc tương tự áp dụng cho ép kiểu: bạn không thể ép kiểu “bush” trực tiếp thành “tree”, ngay cả khi chúng có cùng các trường, nhưng bạn có thể ép kiểu “plant” thành “bush”.
Tuy nhiên, nếu bạn thực sự cần ép kiểu loại “bush” thành “tree”, bạn có thể use unions. Tuy nhiên, bạn nên lưu ý các hạn chế đối với union được mô tả trong phần liên quan của bài viết này. Nói ngắn gọn, bất kỳ trường số nào cũng có thể được chuyển đổi dễ dàng.
//---
enum ENUM_LEAVES
{
rounded,
oblong,
pinnate
};
//---
struct Tree
{
int trunks;
ENUM_LEAVES leaves;
};
//---
struct Bush
{
int trunks;
ENUM_LEAVES leaves;
};
//---
union Plant
{
Bush bush;
Tree tree;
};
//---
void OnStart()
{
Tree tree = {1, rounded};
Bush bush;
Plant plant;
// bush = tree; // Lỗi!
// bush = (Bush) tree; // Lỗi!
plant.tree = tree;
bush = plant.bush; // Không vấn đề...
Print(EnumToString(bush.leaves));
}
//+------------------------------------------------------------------+Ví dụ 7. Chuyển đổi kết cấu bằng union.
Tạm thời dừng ở đây. Mô tả đầy đủ về all khả năng của kết cấu chứa nhiều chi tiết và sắc thái hơn những gì được mô tả trong bài viết này. Bạn có thể muốn so sánh kết cấu MQL5 với các ngôn ngữ khác hoặc tìm hiểu thêm chi tiết. Trong trường hợp này, vui lòng kiểm tra tài liệu tham khảo ngôn ngữ.
Nhưng đối với người mới bắt đầu, theo ý kiến của tôi, tài liệu viết về kết cấu là khá đủ, vì vậy tôi chuyển sang phần tiếp theo.
Union (Liên kết)
Đối với một số nhiệm vụ, bạn có thể cần diễn giải dữ liệu trong one memory cell dưới dạng các biến của different types. Thường gặp nhất, các vấn đề như vậy xuất hiện khi chuyển đổi kiểu kết cấu. Các yêu cầu tương tự cũng có thể phát sinh trong quá trình mã hóa.
Việc mô tả dữ liệu như vậy hầu như không khác gì so với mô tả các kết cấu đơn giản:
// Tạo một kiểu
union AnyNumber {
long integerSigned; // Bất kỳ kiểu dữ liệu hợp lệ nào (xem thêm)
ulong integerUnsigned;
double doubleValue;
};
// Sử dụng
AnyNumber myVariable;
myVariable.integerSigned = -345;
Print(myVariable.integerUnsigned);
Print(myVariable.doubleValue);Ví dụ 8. Sử dụng union.
Để tránh lỗi trong union, nên sử dụng dữ liệu có kiểu chiếm cùng không gian bộ nhớ (mặc dù điều này có thể không cần thiết hoặc thậm chí có hại với some chuyển đổi).
Các kiểu dữ liệu sau không thể là thành viên của union:
- Mảng động
- Chuỗi
- Con trỏ đến đối tượng và hàm
- Đối tượng lớp
- Đối tượng kết cấu có hàm tạo hoặc hàm hủy
- Đối tượng của kết cấu có các phần tử từ các điểm 1-5
Không có hạn chế nào khác áp dụng.
Hãy nhớ điều này: nếu kết cấu của bạn sử dụng bất kỳ trường chuỗi nào, trình biên dịch sẽ báo lỗi. Luôn luôn ghi nhớ điều này.
Hiểu biết cơ bản về Lập trình Hướng Đối tượng
Lập trình hướng đối tượng là một mô hình lập trình cơ bản cho nhiều ngôn ngữ lập trình. Trong cách tiếp cận này, mọi thứ xảy ra trong chương trình được chia thành các khối riêng biệt. Mỗi khối như vậy mô tả một “thực thể” nhất định: một tệp, một đường thẳng, một cửa sổ, một danh sách giá, v.v.
Mục đích của mỗi khối là thu thập dữ liệu và các hành động cần thiết để xử lý nó ở một nơi. Nếu các khối được xây dựng đúng cách, cấu trúc này mang lại nhiều lợi ích:
- Cho phép tái sử dụng mã nhiều lần
- Hỗ trợ hoạt động của IDE, cung cấp khả năng thay thế nhanh chóng tên của các biến và hàm liên quan đến các đối tượng cụ thể
- Giúp dễ dàng tìm lỗi và giảm khả năng thêm lỗi mới
- Hỗ trợ các hoạt động song song cho những người khác nhau (hoặc thậm chí các nhóm) làm việc trên các phần khác nhau của mã
- Giúp dễ dàng thay đổi mã của bạn, ngay cả khi đã qua rất nhiều thời gian
- Tất cả điều này cuối cùng dẫn đến việc phát triển chương trình nhanh hơn, tăng độ tin cậy và mã hóa dễ dàng hơn.
Cấu trúc như vậy nói chung là tự nhiên, vì nó tuân theo các nguyên tắc của cuộc sống hàng ngày. Chúng ta luôn classify tất cả các loại đối tượng: “Thứ này thuộc về class động vật, thứ kia thuộc về thực vật, thứ khác là đồ nội thất”, v.v. Đồ nội thất, đến lượt nó, có thể là tủ hoặc bọc đệm. Và cứ thế.
Tất cả các phân loại này sử dụng một số features nhất định của các đối tượng và mô tả của chúng. Ví dụ, thực vật có thân và rễ, còn động vật có chi chuyển động mà chúng có thể di chuyển. Vì vậy, mỗi lớp có một số attributes đặc trưng. Trong lập trình cũng vậy.
Nếu bạn đặt mục tiêu tạo một thư viện để làm việc với các đường thẳng, bạn cần hiểu rõ mỗi đường thẳng có thể do gì và nó has for it cái gì. Ví dụ, bất kỳ đường thẳng nào cũng has điểm bắt đầu, điểm kết thúc, độ dày và màu sắc.
Đây là các properties hoặc attributes hoặc fields của lớp đường thẳng. Đối với hành động, bạn có thể sử dụng các động từ “vẽ”, “di chuyển”, “sao chép với một khoảng cách nhất định”, “xoay một góc nhất định”, và các hành động khác.
Nếu một đối tượng đường thẳng có thể tự thực hiện tất cả các hành động này, thì lập trình viên nói về methods của đối tượng này.
Các thuộc tính và phương thức cùng nhau được gọi là thành viên (elements) của lớp.
Vì vậy, để tạo một đường thẳng bằng cách tiếp cận này, trước tiên bạn cần tạo một lớp (mô tả) của đường thẳng này - và tất cả các đường thẳng khác trong chương trình - sau đó thông báo cho trình biên dịch: “Những biến này are đường thẳng, và hàm này uses chúng.”
Lớp là một
variable type, chứa mô tả vềpropertiesvàmethodscủa các đối tượng thuộc về lớp này.
Về cách mô tả, một lớp rất giống với một kết cấu. Sự khác biệt chính là theo mặc định, tất cả các thành viên của một lớp chỉ có thể truy cập được trong lớp đó. Trong một kết cấu, tất cả các thành viên của nó đều có thể truy cập được bởi tất cả các hàm của chương trình của chúng ta. Dưới đây là sơ đồ chung để tạo lớp mong muốn:
// mô tả lớp (kiểu biến)
class TestClass { // Tạo một kiểu
private: // Mô tả các biến và hàm riêng tư
// Chúng chỉ có thể truy cập được bởi các hàm trong lớp
// Mô tả dữ liệu (các "thuộc tính" hoặc "trường" của lớp)
double m_privateField;
// Mô tả các hàm (các "phương thức" của lớp)
bool Private_Method(){return false;}
public: // Mô tả các biến và hàm công khai
// Chúng sẽ khả dụng cho tất cả các hàm sử dụng các đối tượng của lớp này
// Mô tả dữ liệu (các "thuộc tính", "trường", hoặc "thành viên" của lớp)
int m_publicField;
// Mô tả các hàm (các "phương thức" của lớp)
void Public_Method(void)
{
Print("Value of `testElement` is ", testElement );
}
}; Ví dụ 9. Mô tả cấu trúc lớp.
Các từ khóa public: và private: xác định các vùng khả năng hiển thị của các thành viên lớp.
Mọi thứ bên dưới từ public: sẽ available “bên ngoài” lớp, tức là cho các hàm khác của chương trình của chúng ta, ngay cả những hàm không thuộc về lớp này.
Mọi thứ phía trên phần này (và bên dưới từ private:) sẽ bị “ẩn”, và quyền truy cập vào các phần tử này sẽ only khả dụng cho các hàm của same class.
Một lớp có thể chứa bất kỳ số lượng phần
public:vàprivate:nào.
Tuy nhiên, mặc dù có gợi ý trong hộp, tốt hơn là better chỉ sử dụng một khối cho mỗi phạm vi (một private: và một public:) để tất cả dữ liệu hoặc hàm có cùng mức truy cập nằm gần nhau. Một số nhà phát triển có kinh nghiệm vẫn thích tạo bốn phần - hai (private và public) cho hàm và hai cho biến. Bây giờ tùy bạn quyết định.
Về cơ bản, từ private: có thể được bỏ qua, vì tất cả các thành viên của lớp không được khai báo là public: sẽ mặc định là private (khác với kết cấu). Nhưng không nên làm điều này, vì mã như vậy sẽ trở nên khó đọc.
Điều quan trọng cần nhớ là
in general, ít nhất mộtfunctiontrong lớp được mô tả phải là “public”, nếu không lớp sẽ vô dụng trong hầu hết các trường hợp. Có những ngoại lệ, nhưng hiếm.
Việc được coi là thực hành lập trình tốt là đặt only functions (không phải biến) trong phần public: để bảo vệ dữ liệu. Điều này cho phép các biến lớp chỉ được sửa đổi thông qua các phương thức của lớp đó. Cách tiếp cận này tăng độ tin cậy của mã chương trình.
Để use một lớp đã mô tả, các variables của kiểu cần thiết được tạo ra ở vị trí mong muốn trong chương trình. Các biến được tạo theo cách thông thường. Quyền truy cập vào các phương thức và thuộc tính của mỗi biến như vậy thường được thực hiện thông qua ký hiệu chấm, như trong kết cấu:
// Mô tả biến của kiểu cần thiết
TestClass myTestClassVariable;
// Sử dụng khả năng của biến này
myTestClassVariable.testElement = 5;
myTestClassVariable.PrintTestElement();Ví dụ 10. Sử dụng một lớp.
Để minh họa cách hoạt động của các thuộc tính public và private, hãy thử dán mã từ Ví dụ 11 vào định nghĩa hàm OnStart của script của bạn và biên dịch tệp. Việc biên dịch sẽ thành công.
Sau đó, thử bỏ ghi chú dòng “myVariable.a = 5;” và biên dịch lại mã. Trong trường hợp này, bạn sẽ nhận được lỗi biên dịch cho biết rằng bạn đang cố gắng truy cập các thành viên private của một lớp. Tính năng này của trình biên dịch giúp loại bỏ một số lỗi tinh vi mà lập trình viên có thể mắc phải khi làm việc với các cách tiếp cận khác.
class PrivateAndPublic
{
private:
int a;
public:
int b;
};
PrivateAndPublic myVariable;
// myVariable.a = 5; // Lỗi biên dịch!
myVariable.b = 10; // Thành côngVí dụ 11. Sử dụng các thuộc tính public và private của một lớp.
Nếu chúng ta phải tự viết tất cả các lớp, cách tiếp cận này sẽ không khác gì so với các cách khác, và sẽ ít có ý nghĩa.
May mắn thay, nhiều lớp tiêu chuẩn đã có sẵn trong thư mục MQL5\Include. Ngoài ra, rất nhiều thư viện hữu ích có thể được tìm thấy trong Code Base. Trong nhiều trường hợp, chúng ta chỉ cần bao gồm tệp phù hợp (như được mô tả dưới đây) để tận dụng những phát triển của người khác. Điều này rất hữu ích cho lập trình viên.
Những cuốn sách đồ sộ được dành riêng cho OOP, và nó chắc chắn xứng đáng có một bài viết riêng. Tuy nhiên, mục đích của bài viết này chỉ đơn giản là cung cấp cho người mới bắt đầu ý tưởng về cách sử dụng các kiểu dữ liệu phức tạp trong chương trình. Bây giờ bạn đã biết cách định nghĩa một lớp cơ bản và cách sử dụng các lớp của người khác, tôi sẽ chuyển sang phần tiếp theo.
Kiểu dữ liệu hàm (toán tử typedef)
Cảnh báo. Phần này có thể khó đối với người mới bắt đầu, vì vậy bạn có thể bỏ qua nó khi đọc bài viết lần đầu tiên.
Việc hiểu tài liệu trong phần này sẽ không ảnh hưởng đến sự hiểu biết của bạn về phần còn lại của tài liệu - hoặc thậm chí, có lẽ, toàn bộ hành trình lập trình của bạn. Hầu hết các vấn đề có thể có nhiều giải pháp, và các kiểu hàm có thể dễ dàng tránh được.
Tuy nhiên, khả năng gán một số hàm nhất định cho một biến (và do đó, trong một số trường hợp, sử dụng chúng làm đối số cho các hàm khác) có thể tiện lợi, và tôi nghĩ rằng值得 biết về khả năng này, ít nhất để có thể đọc mã của người khác.
Đôi khi hữu ích khi tạo các biến của kiểu “hàm”, ví dụ để truyền chúng làm đối số cho một hàm khác.
Ví dụ, trong tình huống giao dịch, lệnh mua và bán rất giống nhau và chỉ khác nhau ở một tham số. Tuy nhiên, giá mua luôn là Ask, và giá bán luôn là Bid.
Thường thì lập trình viên viết các hàm Buy và Sell của riêng họ, tính đến tất cả các sắc thái của một lệnh cụ thể. Sau đó, họ viết một hàm như Trade, kết hợp cả hai khả năng này và trông giống nhau cả khi giao dịch “lên” lẫn “xuống”. Điều này tiện lợi vì Trade tự thay thế các lời gọi đến các hàm Buy hoặc Sell đã viết tùy thuộc vào hướng di chuyển giá được tính toán, và lập trình viên có thể tập trung vào thứ khác.
Bạn có thể nghĩ ra nhiều trường hợp khi bạn muốn nói: “Robot, làm đi!” và để hàm quyết định tùy chọn nào nên được gọi trong một tình huống nhất định. Khi tính toán take profit, số điểm nên được cộng hay trừ khỏi giá? Khi tính toán stop loss? Khi đặt lệnh tại một cực trị, nó nên tìm cực đại hay cực tiểu? Và cứ thế.
Trong những trường hợp như vậy, cách tiếp cận được mô tả dưới đây đôi khi được sử dụng.
Như thường lệ, trước tiên bạn cần mô tả kiểu của biến bạn cần. Trong trường hợp này, kiểu này được mô tả bằng mẫu sau:
typedef function_result_type (*Function_type_name)(input_parameter1_type,input_parameter1_type ...); Ví dụ 12. Mẫu để mô tả một kiểu hàm.
Trong đó:
function_result_typelà kiểu của giá trị trả về (bất kỳ kiểu hợp lệ nào, chẳng hạn như int, double, v.v.).Function_type_namelà tên của kiểu mà chúng ta sẽ sử dụng khi tạo biến.input_parameter1_typelà kiểu của tham số đầu tiên. Danh sách tham số tuân theo quy tắc của danh sách hàm thông thường.
Lưu ý dấu sao (*) trước tên kiểu. Nó rất quan trọng, và nếu không có nó thì không gì hoạt động được.
Nó có nghĩa là biến của kiểu này sẽ không chứa kết quả hay một số, mà là chính hàm đó, với đầy đủ các khả năng, và do đó, biến này sẽ kết hợp các khả năng vốn có của cả biến khác và hàm.
Một cấu trúc như vậy, khi mô tả một kiểu dữ liệu, sử dụng chính đối tượng đó (một hàm, một đối tượng của một lớp nào đó, v.v.), chứ không phải bản sao của dữ liệu đối tượng hoặc kết quả hoạt động của nó, được gọi là con trỏ.
Chúng ta sẽ nói thêm về con trỏ trong các bài viết sau. Hãy xem một ví dụ hoạt động của việc sử dụng toán tử typedef.
Giả sử chúng ta có các hàm Diff và Add, mà chúng ta muốn gán cho một biến nào đó. Cả hai hàm đều trả về giá trị nguyên và nhận hai tham số nguyên. Việc triển khai của chúng rất đơn giản:
//---
int Add (int a,int b)
{
return (a+b);
}
//---
int Diff (int a,int b)
{
return (a-b);
}Ví dụ 13. Hàm cộng và hiệu để kiểm tra kiểu hàm.
Hãy mô tả kiểu TFunc cho các biến có thể lưu trữ bất kỳ hàm nào trong số này:
typedef int (*TFunc) (int, int);Ví dụ 14. Khai báo kiểu cho các biến có thể lưu trữ hàm Add và Diff.
Bây giờ hãy kiểm tra cách mô tả này sẽ hoạt động:
void OnStart()
{
TFunc operate; //Như thường lệ, chúng ta khai báo một biến của kiểu đã mô tả
operate = Add; // Ghi một giá trị vào biến (trong trường hợp này, gán một hàm)
Print(operate(3, 5)); // Sử dụng biến như một hàm bình thường
// Đầu ra của hàm: 8
operate=Diff;
Print(operate(3, 5)); // Đầu ra của hàm: -2
}Ví dụ 15. Sử dụng một biến của kiểu hàm.
Tôi muốn lưu ý rằng toán tử typedef only hoạt động với các hàm custom.
Bạn không thể sử dụng trực tiếp các hàm tiêu chuẩn như MathMin hoặc tương tự, nhưng bạn có thể tạo một “wrapper” cho chúng. Ví dụ:
//---
double MyMin(double a, double b){
return (MathMin(a,b));
}
//---
double MyMax(double a, double b){
return (MathMax(a,b));
}
//---
typedef double (*TCompare) (double, double);
//---
void OnStart()
{
TCompare extremumOfTwo;
compare= MyMin;
Print(extremumOfTwo(5, 7));// 5
compare= MyMax;
Print(extremumOfTwo(5, 7));// 7
}Ví dụ 16. Sử dụng wrapper để làm việc với các hàm tiêu chuẩn.
Bao gồm các tệp bên ngoài (chỉ thị tiền xử lý #include)
Bất kỳ chương trình nào cũng có thể được chia thành nhiều mô-đun.
Nếu bạn đang làm việc với các dự án lớn, việc chia nhỏ là bắt buộc. Tính mô-đun của chương trình giải quyết nhiều vấn đề cùng lúc.
- Thứ nhất, mã mô-đun dễ điều hướng hơn.
- Thứ hai, nếu bạn làm việc nhóm, mỗi mô-đun có thể được phát triển bởi những người khác nhau, điều này tăng tốc quá trình rất nhiều.
- Và thứ ba, các mô-đun đã tạo có thể được tái sử dụng.
Mô-đun rõ ràng nhất là một hàm. Hơn nữa, bạn có thể tạo mô-đun cho tất cả các hằng số, một số mô tả kiểu dữ liệu phức tạp, sự kết hợp của nhiều hàm liên quan (ví dụ, các hàm để thay đổi giao diện của đối tượng hoặc các hàm toán học), v.v.
Trong các dự án lớn, rất tiện lợi khi đặt các khối mã như vậy vào các tệp riêng biệt, sau đó bao gồm các tệp này vào chương trình hiện tại.
Để bao gồm các additional text files vào một chương trình, chúng ta sử dụng chỉ thị tiền xử lý #include:
#include <SomeFile.mqh> // Dấu ngoặc nhọn chỉ định tìm kiếm tương đối với thư mục MQL5\Include
#include "AnyOtherPath.mqh" // Dấu ngoặc kép chỉ định tìm kiếm tương đối với tệp hiện tạiVí dụ 17. Hai dạng của #include.
Nếu trình biên dịch gặp chỉ thị #include ở bất kỳ đâu trong mã của bạn, nó sẽ cố gắng chèn nội dung của tệp được chỉ định
in place of this instruction, nhưngonly once per program. Nếu tệp đã được sử dụng, nó không thể được bao gồm lần thứ hai.
Bạn có thể kiểm tra câu lệnh này bằng script được mô tả trong phần tiếp theo.
Thường thì các tệp được bao gồm được đặt phần mở rộng *.mqh, vì điều này tiện lợi, nhưng nói chung phần mở rộng có thể là bất kỳ.
Script để kiểm tra hoạt động của chỉ thị #include
Để kiểm tra hành động của trình biên dịch khi gặp chỉ thị tiền xử lý này, chúng ta cần tạo two files.
Trước tiên, hãy tạo một tệp có tên “1.mqh” trong thư mục scripts (MQL5\Scripts). Nội dung của tệp này sẽ rất đơn giản:
Print("This is include with number "+i);Ví dụ 18. Tệp bao gồm đơn giản nhất có thể chỉ chứa một lệnh.
Tôi hy vọng rõ ràng mã này làm gì. Giả sử rằng một biến i đã được khai báo ở đâu đó, mã này tạo một thông điệp cho người dùng bằng cách thêm giá trị của một biến vào thông điệp, sau đó in thông điệp đó vào nhật ký.
Biến i sẽ là một dấu hiệu cho biết lệnh được gọi ở điểm nào trong script. Nothing khác nên được viết trong tệp this. Bây giờ, in the same directory, (nơi tệp “1.mqh” nằm) chúng ta tạo một script chứa mã sau:
//+------------------------------------------------------------------+
//| Script program start function |
//+------------------------------------------------------------------+
void OnStart()
{
//---
int i=1;
#include "1.mqh"
i=2;
#include "1.mqh"
}
//+------------------------------------------------------------------+
// Đầu ra của script:
//
// This is include with number 1
//
// Nỗ lực thứ hai để sử dụng cùng một tệp sẽ bị bỏ qua
//+------------------------------------------------------------------+ Ví dụ 19. Kiểm tra việc bao gồm lặp lại một tệp.
Trong mã này, chúng ta đã cố gắng sử dụng tệp “1.mqh” twice để nhận hai thông điệp kích hoạt.
Khi chúng ta chạy script này trong terminal, chúng ta sẽ thấy rằng thông điệp đầu tiên hoạt động như kỳ vọng, hiển thị số 1 trong thông điệp, nhưng thông điệp thứ hai không xuất hiện.
Tại sao hạn chế này được áp dụng? Tại sao tệp không thể được sử dụng nhiều lần?
Đây là một nguyên tắc quan trọng vì các tệp bao gồm thường chứa khai báo của các biến và hàm. Bạn đã biết, trong một chương trình ở cấp độ toàn cục (bên ngoài tất cả các hàm) chỉ nên có một biến với một tên nhất định.
Nếu, ví dụ, biến int a; được khai báo, thì biến chính xác như vậy không thể được khai báo lần thứ hai ở cấp độ này. Bạn chỉ có thể sử dụng biến đã tồn tại. Đối với các hàm, tình hình phức tạp hơn một chút nhưng ý tưởng thì giống nhau: mỗi hàm phải là duy nhất trong chương trình của chúng ta. Bây giờ hãy tưởng tượng rằng chương trình sử dụng hai mô-đun độc lập, nhưng mỗi mô-đun bao gồm cùng một lớp tiêu chuẩn nằm trong tệp <Arrays\List.mqh> (Hình 2).
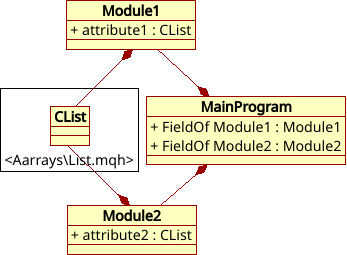
Hình 2. Sử dụng cùng một lớp bởi hai mô-đun.
Nếu không có hạn chế đó, trình biên dịch sẽ trả về thông báo lỗi, vì việc khai báo cùng một lớp hai lần là bị cấm. Nhưng trong trường hợp này, cấu trúc như vậy hoàn toàn khả thi, vì sau khi mô tả trường FieldOf_Module1, mô tả CList đã được bao gồm trong danh sách của trình biên dịch, và do đó chỉ đơn giản là sử dụng mô tả này cho mô-đun 2.
Hiểu nguyên tắc này, bạn có thể tạo ra ngay cả sự lồng ghép “đa tầng”, ví dụ, khi một số phần tử lớp phụ thuộc lẫn nhau “theo vòng tròn”, như trong Hình 3.
Bạn thậm chí có thể mô tả một biến của cùng một lớp bên trong một lớp.
Tất cả những điều này là các cấu trúc chấp nhận được, vì #include hoạt động chính xác một lần cho một tệp.
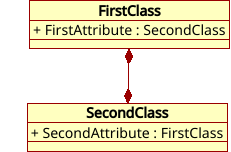
Hình 3. Phụ thuộc vòng tròn: mỗi lớp chứa các phần tử phụ thuộc vào lớp khác.
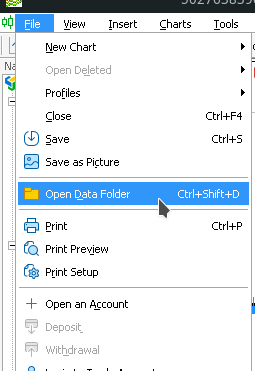
Kết luận phần này, tôi muốn nhắc lại một lần nữa rằng các files của các standard libraries MetaTrader 5, mà bạn có thể bao gồm vào mã của mình, nằm trong thư mục MQL5\Include. Để open this directory in explorer, chọn menu “File” -> “Open data directory” trong terminal MetaTrader (Hình 4).
Hình 4. Cách mở thư mục dữ liệu.
Nếu bạn muốn mở các tệp từ thư mục này trong MetaEditor, hãy tìm thư mục Include trong bảng điều hướng. Bạn có thể tạo các tệp bao gồm của riêng mình trong cùng thư mục (tốt nhất là trong các thư mục riêng biệt), hoặc bạn có thể sử dụng thư mục của chương trình của mình và các thư mục con của nó (xem bình luận trong ví dụ 17). Theo quy tắc, các chỉ thị #include được sử dụng at the beginning of the file, trước khi tất cả các hành động khác bắt đầu. Tuy nhiên, quy tắc này không nghiêm ngặt, và mọi thứ phụ thuộc vào các nhiệm vụ cụ thể.
Kết luận
Hãy để tôi một lần nữa liệt kê ngắn gọn các chủ đề đã được thảo luận trong bài viết này.
- Chúng ta đã đề cập đến chỉ thị tiền xử lý #include, cho phép chúng ta bao gồm các tệp văn bản bổ sung vào chương trình của mình, thường là một số thư viện.
- Chúng ta đã thảo luận về các kiểu dữ liệu phức tạp: structures, unions, và objects (các biến dựa trên classes), cũng như functional data types.
Tôi hy vọng rằng giờ đây các kiểu dữ liệu được mô tả trong bài viết này chỉ “phức tạp” đối với bạn về cấu trúc, chứ không phải về ứng dụng.
Không giống như các kiểu đơn giản, được tích hợp sẵn trong ngôn ngữ, các kiểu “phức tạp” phải được khai báo trước, sau đó mới có thể tạo biến. Tuy nhiên, làm việc với dữ liệu như vậy về cơ bản không khác gì làm việc với các kiểu “đơn giản”: bạn tạo biến và gọi các thành phần (thành viên) của các biến này (nếu có) hoặc sử dụng tên biến như tên hàm nếu bạn đã tạo một kiểu hàm.
Việc khởi tạo các biến được tạo bằng kết cấu có thể được thực hiện bằng dấu ngoặc nhọn.
Tôi hy vọng bạn giờ đây hiểu rằng khả năng tạo các kiểu phức tạp your own và chia chương trình thành các mô-đun được lưu trữ trong các tệp bên ngoài khiến việc phát triển chương trình trở nên linh hoạt và tiện lợi.


